Prometheus est un outil populaire et puissant pour surveiller Kubernetes. Mais comment s’y prendre pour démarrer avec Prometheus et le Monitoring ?
Construit par SoundCloud à partir de 2012, Prometheus est un logiciel libre de premier plan pour :
- l’instrumentation
- la collecte
- le stockage de données métriques,
Depuis cette date, il a été donné à la Cloud Native Computing Foundation et est devenu la norme de facto pour la surveillance de Kubernetes.
Quelle est la façon d’utiliser Prometheus sur Kubernetes ? Cet article :
- Décrit l’architecture et le modèle de données de Prometheus pour vous aider à comprendre son fonctionnement et ses possibilités
- Propose un tutoriel sur l’installation de Prometheus dans un cluster Kubernetes et son utilisation pour surveiller les clusters et les applications
Architecture
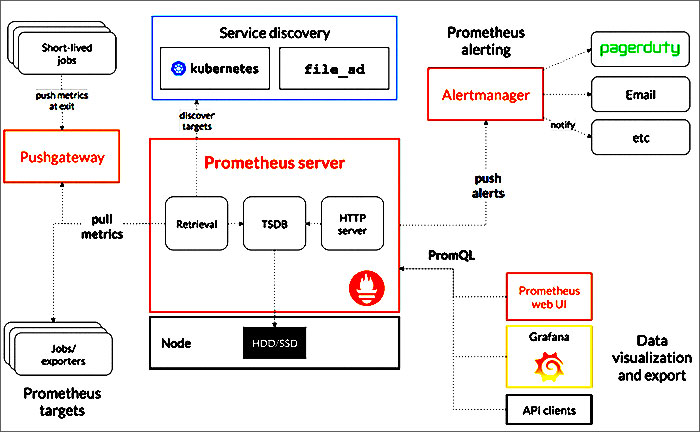
L’architecture de Prometheus
Les trois composantes de Prometheus
Pour la plupart des cas d’utilisation, vous devez visualiser 3 composantes majeures de Prometheus :
- Le serveur Prometheus stocke les données métriques. Il utilise une couche de persistance, qui fait partie du serveur et qui n’est pas expressément mentionnée dans la documentation. Chaque nœud du serveur est autonome et ne repose pas sur un stockage distribué.
- L’interface web vous permet d’accéder aux données stockées, de les visualiser et de les représenter sous forme de graphiques. Prometheus fournit sa propre interface utilisateur, mais vous pouvez également configurer d’autres outils de visualisation, comme Grafana, pour accéder au serveur Prometheus en utilisant PromQL (le langage de requête de Prometheus).
- Alertmanager envoie des alertes à partir des applications clientes, en particulier le serveur Prometheus. Il dispose de fonctionnalités avancées pour dédupliquer, regrouper et acheminer les alertes et peut les acheminer par le biais d’autres services comme PagerDuty et OpsGenie.
La clé de la compréhension de Prometheus est qu’il repose fondamentalement sur l’extraction de mesures à partir de points finaux définis.
Cela signifie que votre application doit exposer un point d’extrémité pour lequel des mesures sont disponibles et indiquer au serveur Prometheus comment les extraire.
Il existe des exportateurs pour de nombreuses applications qui ne disposent pas d’un moyen facile d’ajouter des terminaux web, comme Kafka et Cassandra (en utilisant l’exportateur JMX).
Le modèle de données
Maintenant que l’ont sait comment Prometheus fonctionne pour stocker les mesures, la prochaine chose à apprendre est le type de mesures que Prometheus peut prendre.
Compteurs et jauges
Les deux types métriques les plus simples sont le compteur et la jauge.
Avec Prometheus Monitoring (ou plus généralement avec la surveillance des séries chronologiques), ce sont les types les plus faciles à comprendre car il est facile de les relier à des valeurs que vous pouvez imaginer pour la surveillance, comme la quantité de ressources système utilisée par votre application ou le nombre d’événements traités.
- Un compteur est une métrique cumulative qui représente un compteur à croissance dont la valeur ne peut qu’augmenter ou être remise à zéro au redémarrage. Par exemple, vous pouvez utiliser un compteur pour représenter le nombre de demandes, de tâches accomplies ou d’erreurs.
- Une jauge est une métrique qui représente une valeur numérique unique qui peut arbitrairement monter et descendre. Les jauges sont généralement utilisées pour des valeurs mesurées comme le processeur ou l’utilisation de la mémoire, mais aussi pour des comptes qui peuvent monter et descendre, comme le nombre de requêtes simultanées.
Histogrammes et résumés
Prometheus supporte deux types de métriques plus complexes : les histogrammes et les résumés.
Il y a ici de nombreuses possibilités de confusion, étant donné qu’ils suivent tous deux le nombre d’observations et la somme des valeurs observées. L’une des raisons pour lesquelles vous pourriez choisir de les utiliser est que vous devez calculer une moyenne des valeurs observées.
Ils créent de multiples séries temporelles dans la base de données ; par exemple, ils créent chacun une somme des valeurs observées avec un suffixe _sum.
Un histogramme échantillonne les observations (la durée des demandes et la taille des réponses) et les compte dans des buckets configurables. Il fournit également une somme de toutes les valeurs observées.
Cela en fait un excellent candidat pour suivre des choses comme la latence.
La différence essentielle entre les résumés et les histogrammes est que les résumés calculent les quantiles du streaming φ-quantiles du côté client et les exposent directement, tandis que les histogrammes exposent les comptes d’observations par tranche.
Le calcul des quantiles des tranches d’un histogramme se fait du côté serveur en utilisant la fonction histogram_quantile().
Si c’est confus, je vous suggère d’adopter l’approche suivante :
- Utilisez des jauges la plupart du temps pour des mesures de séries chronologiques simples.
- Utilisez des compteurs pour les choses dont vous savez qu’elles augmentent de façon monotone, par exemple si vous comptez le nombre de fois qu’une chose se produit.
- Utilisez des histogrammes pour les mesures de latence avec des buckets simples.
Cela devrait être suffisant pour la grande majorité des cas d’utilisation, de toute façon vous devrez faire appel à un expert en analyse statistique pour vous aider dans les scénarios plus avancés.
Maintenant que vous avez une compréhension de base de ce qu’est Prometheus, de son fonctionnement et des types de données qu’il peut collecter et stocker, vous êtes prêt à commencer le tutoriel.
Tutoriel pratique sur Prometheus et Kubernetes
Ce tutoriel couvre les points suivants :
- Installer Prometheus dans votre cluster pour le monitoring
- Téléchargement de l’exemple de demande et examen du code
- Création et déploiement de l’application et génération de la charge correspondante
- Accès à l’interface de Prometheus et examen des paramètres de base
Ce tutoriel suppose :
- Vous avez déjà déployé un cluster Kubernetes
- Vous avez configuré l’utilitaire de ligne de commande kubectl pour l’accès
- Vous avez le rôle d’administrateur du cluster (ou au moins des privilèges suffisants pour créer des espaces de noms et déployer des applications)
- Vous utilisez une interface en ligne de commande basée sur Bash. Ajustez ce tutoriel si vous utilisez d’autres systèmes d’exploitation ou environnements shell.
Installer Prometheus
Dans cette section, vous clonerez le dépôt d’échantillons et utiliserez les fichiers de configuration de Kubernetes pour déployer Prometheus dans un espace de noms dédié.
Clonez le dépôt d’échantillons localement et utilisez-le comme répertoire de travail
$ git clone https://github.com/yuriatgoogle/prometheus-demo.git
$ cd prometheus-demo
$ WORKDIR=$(pwd)
Créer un namespace dédié pour le déploiement de Prometheus
$ kubectl create namespace prometheus
Donnez au cluster le rôle de leader
$ kubectl apply -f $WORKDIR/kubernetes/clusterRole.yaml
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
Créer une configmap Kubernetes avec des règles de scraping et d’alerte
$ kubectl apply -f $WORKDIR/kubernetes/configMap.yaml -n prometheus
configmap/prometheus-server-conf created
Déployer Prometheus
$ kubectl create -f prometheus-deployment.yaml -n prometheus
deployment.extensions/prometheus-deployment created
Vérifier que Prometheus est en cours d’exécution
$ kubectl get pods -n prometheus
NAME READY STATUS RESTARTS AGE
prometheus-deployment-78fb5694b4-lmz4r 1/1 Running 0 15s
Réviser les mesures de base
Dans cette section, vous accéderez à l’interface utilisateur de Prometheus et examinerez les données recueillies.
Utilisez la redirection de port pour permettre l’accès à l’interface utilisateur de Prometheus sur le Web au niveau local
Votre déploiement Prometheus portera un nom différent de celui de cet exemple. Revoyez et remplacez le nom du pod par celui de la sortie de la commande précédente.
$ kubectl port-forward prometheus-deployment-7ddb99dcb-fkz4d 8080:9090 -n prometheus
Forwarding from 127.0.0.1:8080 -> 9090
Forwarding from [::1]:8080 -> 9090
Allez sur http://localhost:8080 dans un navigateur
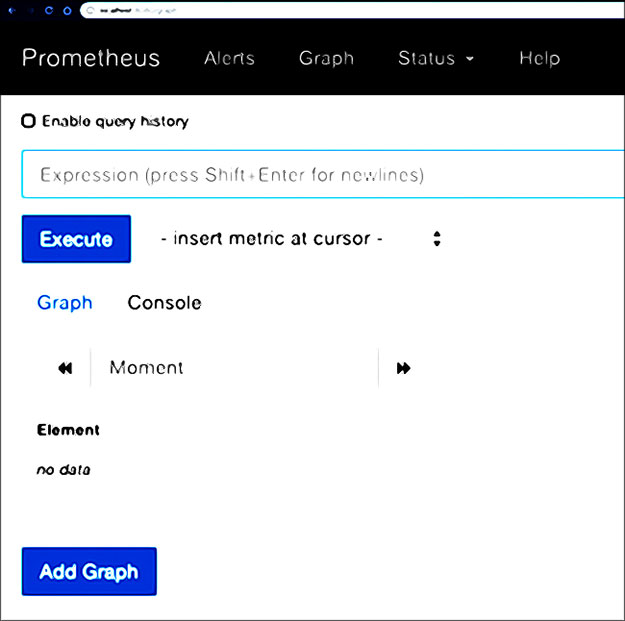
Vous êtes maintenant prêt à interroger les métriques de Prometheus.
Certaines mesures de base de la machine (comme le nombre de cœurs de processeur et la mémoire) sont disponibles immédiatement
Par exemple, entrez machine_memory_bytes dans le champ d’expression, passez en vue Graphique et cliquez sur Exécuter pour voir la métrique sous forme de graphique :
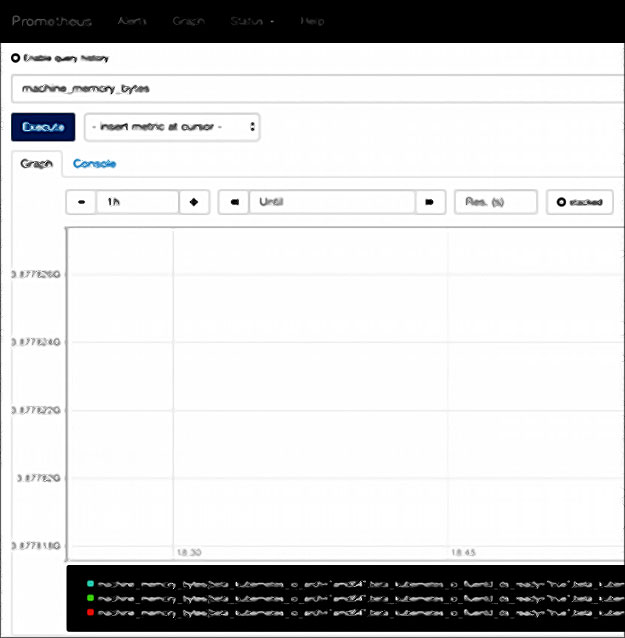
Les conteneurs qui circulent dans le cluster sont surveillés automatiquement
Par exemple, entrez rate(container_cpu_usage_seconds_total{container_name= »prometheus »}[1m]) comme expression et cliquez sur Exécuter pour voir le taux d’utilisation du CPU par Prometheus :
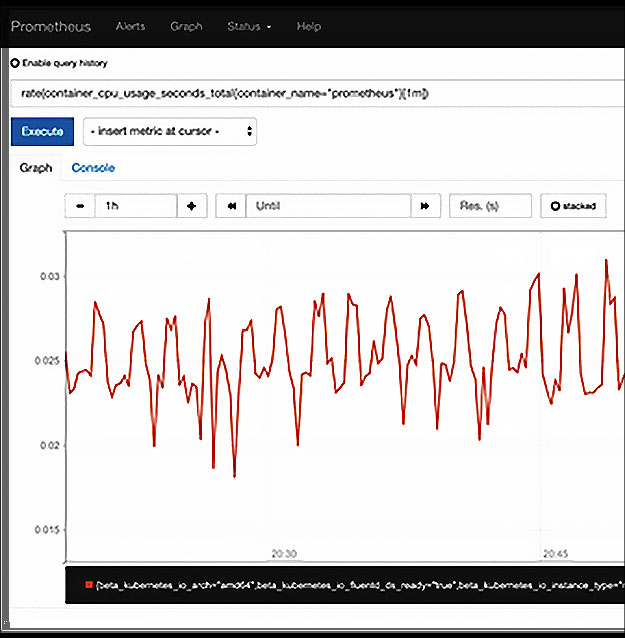
Maintenant que vous savez comment installer Prometheus et l’utiliser pour mesurer des paramètres prêts à l’emploi, il est temps de procéder à un véritable suivi.
Les signaux d’or
Comme décrit dans le chapitre « Monitoring Distributed Systems » du livre SRE de Google :
« Les quatre signaux d’or de la surveillance sont la latence, le trafic, les erreurs et la saturation. Si vous ne pouvez mesurer que quatre paramètres de votre système d’interface utilisateur, concentrez-vous sur ces quatre-là ».
Le livre offre des descriptions détaillées de ces quatre signaux, mais ce tutoriel se concentre sur les trois signaux qui servent le plus facilement de proxy pour le bonheur de l’utilisateur :
- Le trafic : combien de demandes vous recevez
- Taux d’erreur : Combien de ces demandes pouvez-vous traiter avec succès ?
- Latence : La rapidité avec laquelle vous pouvez servir les demandes retenues
Comme vous vous en rendez probablement compte maintenant, Prometheus ne mesure aucun de ces éléments pour vous ; vous devrez instrumenter toute application que vous déployez pour les émettre. Voici un exemple de mise en œuvre.
Ouvrez le fichier $WORKDIR/node/golden_signals/app.js, qui est un exemple d’application écrite dans Node.js (rappelez-vous que nous avons cloné yuriatgoogle/prometheus-demo et exporté $WORKDIR plus tôt). Commencez par examiner la première section, où sont définis les paramètres à enregistrer :
// total requests - counter
const nodeRequestsCounter = new prometheus.Counter({
name: 'node_requests',
help: 'total requests'
});
La première mesure est un compteur qui sera incrémenté pour chaque demande ; c’est ainsi que le nombre total de demandes est compté :
// failed requests - counter
const nodeFailedRequestsCounter = new prometheus.Counter({
name: 'node_failed_requests',
help: 'failed requests'
});
La deuxième mesure est un autre compteur qui s’incrémente pour chaque erreur afin de suivre le nombre de demandes échouées :
NordVPN
Un des leaders mondiaux du VPN avec accès illimité à +5000 serveurs dans 60 pays et un double chiffrement pour une protection maximale.
Fonctionnalités premium :
- ✓ Adresse IP dédiée
- ✓ Serveurs P2P optimisés
- ✓ Intégration TOR intégrée
- ✓ Bloqueur de malwares & pubs
Garantie satisfait ou remboursé 30 jours
// latency - histogram
const nodeLatenciesHistogram = new prometheus.Histogram({
name: 'node_request_latency',
help: 'request latency by path',
labelNames: ['route'],
buckets: [100, 400]
});
La troisième métrique est un histogramme qui suit la latence des demandes. En partant de l’hypothèse très simple que le SLO pour la latence est de 100 ms, vous créerez deux buckets : un pour 100 ms et l’autre pour 400 ms de latence.
- La section suivante traite les demandes entrantes
- incrémente la métrique totale des demandes pour chacune d’entre elles
- incrémente les demandes échouées en cas d’erreur (induite artificiellement)
- enregistre une valeur d’histogramme de latence pour chaque demande réussie
J’ai choisi de ne pas enregistrer les temps de latence pour les erreurs ; c’est à vous de décider des détails de la mise en œuvre.
app.get('/', (req, res) => {
// start latency timer
const requestReceived = new Date().getTime();
console.log('request made');
// increment total requests counter
nodeRequestsCounter.inc();
// return an error 1% of the time
if ((Math.floor(Math.random() * 100)) == 100) {
// increment error counter
nodeFailedRequestsCounter.inc();
// return error code
res.send("error!", 500);
}
else {
// delay for a bit
sleep.msleep((Math.floor(Math.random() * 1000)));
// record response latency
const responseLatency = new Date().getTime() - requestReceived;
nodeLatenciesHistogram
.labels(req.route.path)
.observe(responseLatency);
res.send("success in " + responseLatency + " ms");
}
})
Tester localement
Maintenant que vous avez vu comment mettre en œuvre les mesures de Prometheus, voyez ce qui se passe lorsque vous exécutez l’application.
Installez les paquets nécessaires
$ cd $WORKDIR/node/golden_signals
$ npm install --save
Lancez l’application
$ node app.js
Ouvrez deux onglets du navigateur : l’un vers http://localhost:8080 et l’autre vers http://localhost:8080/metrics
Lorsque vous allez à la page /metrics, vous pouvez voir les mesures de Prometheus collectées et mises à jour à chaque fois que vous rechargez la page d’accueil :
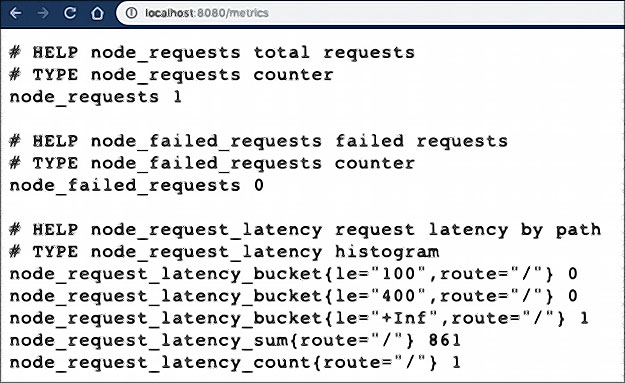
Vous êtes maintenant prêt à déployer l’application modèle dans votre cluster Kubernetes et tester votre surveillance.
Six facteurs à prendre en compte
Pour les entreprises qui commencent avec Prometheus et cherchent ensuite une solution commerciale pour servir une vision globale, il est important qu’elles ne perdent pas tout le travail de développement effectué pour la normalisation sur Prometheus :
- tableaux de bord
- alertes
- exportateurs
- autres travaux
Toutefois, ce n’est pas la seule chose à prendre en compte. Si vous choisissez cette voie, insistez sur le soutien de ces critères fondamentaux :
Une compatibilité totale avec l’ingestion
Votre fournisseur/outil/solution SaaS doit pouvoir consommer les données de toute entité capable de produire des métriques Prometheus, qu’il s’agisse de Kubernetes sur site ou de tout autre service en nuage.
La consommation de mesures Prometheus est relativement insignifiante, mais ne négligez pas les petits détails, comme la possibilité de réétiqueter les mesures au fur et à mesure que vous les intégrez dans le stockage ou d’augmenter les données afin que cela soit plus logique pour votre environnement.
Ces éléments s’additionnent et font une grande différence dans la capacité à utiliser les montagnes de données collectées.

Compatibilité avec PromQL
Le langage de requête Prometheus a été inventé par les créateurs de Prometheus pour extraire les informations stockées par Prometheus.
PromQL vous permet de demander des mesures sur, par exemple, des services spécifiques ou des utilisateurs particuliers. Il vous permet également d’agréger ou de segmenter des données.
Par exemple, vous pouvez l’utiliser pour montrer l’utilisation de l’unité centrale, application par application, pour tous vos conteneurs. Ou pour afficher uniquement les données relatives aux conteneurs Cassandra et les présenter sous la forme d’une valeur unique pour chaque groupe.
PromQL déverrouille la valeur réelle de Prometheus ; par conséquent, l’ingestion des mesures de Prometheus dans un produit qui ne supporte pas entièrement PromQL va à l’encontre de l’objectif de l’utilisation de Prometheus .
Hot-Swappable
Pour être vraiment compatible avec Prometheus, la solution doit être remplaçable à chaud, c’est-à-dire pouvoir fonctionner avec vos tableaux de bord, alertes et scripts existants.
De nombreuses entreprises qui utilisent Prometheus, par exemple, utilisent Grafana pour leurs tableaux de bord. Cet outil open source est parfaitement intégré à Prometheus, y compris au niveau des requêtes, et peut être utilisé pour produire toute une série de graphiques et de tableaux de bord utiles.
Les offres commerciales qui prétendent être compatibles avec Prometheus doivent donc être compatibles avec des outils comme Grafana.
Il ne suffit pas de dire que la solution permet de voir un nombre dans Grafana. Vous devez pouvoir ingérer les tableaux de bord Grafana existants tels quels, sans aucune modification, et les appliquer à nouveau aux données installées dans la solution commerciale.
Contrôles d’accès
Les contrôles d’accès sont une autre question de sécurité que vous devez prendre en compte lors de l’évaluation des outils.
La possibilité de sécuriser l’authentification des utilisateurs à l’aide de protocoles standard du secteur – notamment LDAP, Google Oauth, SAML et OpenID – permet aux entreprises d’isoler et de sécuriser les ressources grâce à un contrôle d’accès basé sur les services.

Dépannage
Kubernetes simplifie le déploiement, la mise à l’échelle et la gestion des applications et des micro-services conteneurisés.
Cela permet de maintenir les services en fonctionnement, mais pour identifier et résoudre les problèmes sous-jacents, tels que la lenteur des performances, les échecs de déploiement et les erreurs de connexion, vous devez pouvoir rassembler et visualiser des données approfondies sur l’infrastructure, les applications et les performances de votre environnement.
Le fait de ne pas avoir accès à la fois aux informations en temps réel et aux données contextuelles rend presque impossible la corrélation des mesures dans votre environnement, ce qui vous permet de résoudre les problèmes plus rapidement.
Compatibilité avec les alertes existantes
Enfin, si vous recherchez une réponse commerciale pour vous aider à résoudre le problème d’évolutivité de Prometheus, assurez-vous qu’il prend en charge tous les niveaux d’alerte.
La clé pour y parvenir est la prise en charge complète de la fonctionnalité Alert Manager, qui nécessite à son tour une ingestion à 100 % et la compatibilité avec PromQL.
Si vous trouvez un outil commercial qui répond à ces critères, vous devriez pouvoir le remplacer par des intégrations Prometheus existantes avec un minimum d’efforts et éviter les problèmes d’extensibilité auxquels les entreprises sont confrontées.
Les développeurs adorent Prometheus, à juste titre, et la diligence raisonnable dont vous faites preuve maintenant vous aidera à vous assurer qu’ils peuvent toujours utiliser les paramètres qu’ils aiment.
⇒ Logiciel espion : types, usages et précautions

Promo spéciale NordVPN : jusqu’à -74 % + data gratuite sur Saily (1 à 10 Go selon l’abonnement).
💡 Sécurise tes connexions et navigue librement en quelques clics.


